
Han Lin
Han Lin is a third-year Ph.D. student at the MURGe-Lab, UNC at Chapel Hill, advised by Prof. Mohit Bansal. He received his M.S. in Computer Science from Columbia University, where he was a member of the DVMM Lab advised by Prof. Shih-Fu Chang and the ROAM Lab advised by Prof. Matei Ciocarlie and Prof. Shuran Song. He also holds an M.S. in Financial Engineering from Columbia and a B.S. in Financial Engineering from Central University of Finance and Economics. He is fortunate to collaborate with Prof. Krzysztof Choromanski from Google Deepmind, and has completed internships with the Movie Gen Team at Meta Superintelligence Labs, and the JEPA Team at Meta FAIR.
His research broadly lies in computer vision, multimodal learning, and theory-grounded efficient algorithms, with a focus on controllable and interactive world modeling.
- Explicit Control via Interpretable Interfaces: equipping visual generation with user-facing handles for controllable image/video synthesis, including CTRL-Adapter, VideoDirectorGPT, EPiC, DreamRunner, DiagrammerGPT, and AnchorWeave.
- Implicit Guidance through Stronger Priors: enriching generative models with multimodal priors, semantic representation alignment, and dynamics-aware future-state prediction, including Bifrost-1, VEDiT, MetaCanvas, V-Co, and SMKD.
- Multimodal LLMs for Planning, Verification & Embodied Tasks: leveraging multimodal LLMs and verifiers for embodied agent training, physics-aware video planning, 3D scene editing, including EnvGen, SketchVerify, VideoMSG, DEER-3D, and Tandem3D.
- Efficient & Theory-Grounded ML: scalable Transformers, kernel methods, random features, and graph neural networks, including HRF, OMC, GKAT, FTFIs, Graph Field Integrators.
Feel free to reach out to me if you would like to chat about any research ideas!
News
∙ [2026-05] PhyMotion released on arXiv
∙ [2026-05] EPiC accepted to ICML 2026
∙ [2026-03] V-Co released on arXiv
∙ [2026-02] AnchorWeave released on arXiv
∙ [2026-01] We are organizing the Any-To-Any Multimodal Learning Workshop at CVPR 2026
∙ [2026-01] Humanity's Last Exam published in Nature
∙ [2025-12] MetaCanvas released on arXiv
∙ [2025-11] SketchVerify released on arXiv
∙ [2025-11] Deer3D released on arXiv
∙ [2025-09] Bifrost-1 accepted to NeurIPS 2025
∙ [2025-05] Started research scientist internship with the Media Generation Team at Meta Superintelligence Labs
∙ [2025-04] Video-MSG released on arXiv
∙ [2025-01] VEDiT accepted to ICLR 2025
∙ [2025-01] CTRL-Adapter accepted to ICLR 2025 as Oral (top 1.82%)
∙ [2024-12] DreamRunner accepted to AAAI 2025
∙ [2024-09] FTFIs accepted to NeurIPS 2024
∙ [2024-07] Three papers (VideoDirectorGPT, EnvGen, DiagrammerGPT) accepted to COLM 2024
∙ [2024-05] Started research scientist internship with the JEPA team at Meta FAIR Lab
Preprints
PhyMotion: Structured 3D Motion Reward for Physics-Grounded Human Video Generation
Yidong Huang*, Zun Wang*, Han Lin, Dong-Ki Kim, Shayegan Omidshafiei, Jaehong Yoon, Jaemin Cho, Yue Zhang, Mohit Bansal
arXiv Preprint, 2026
Paper | Project Page
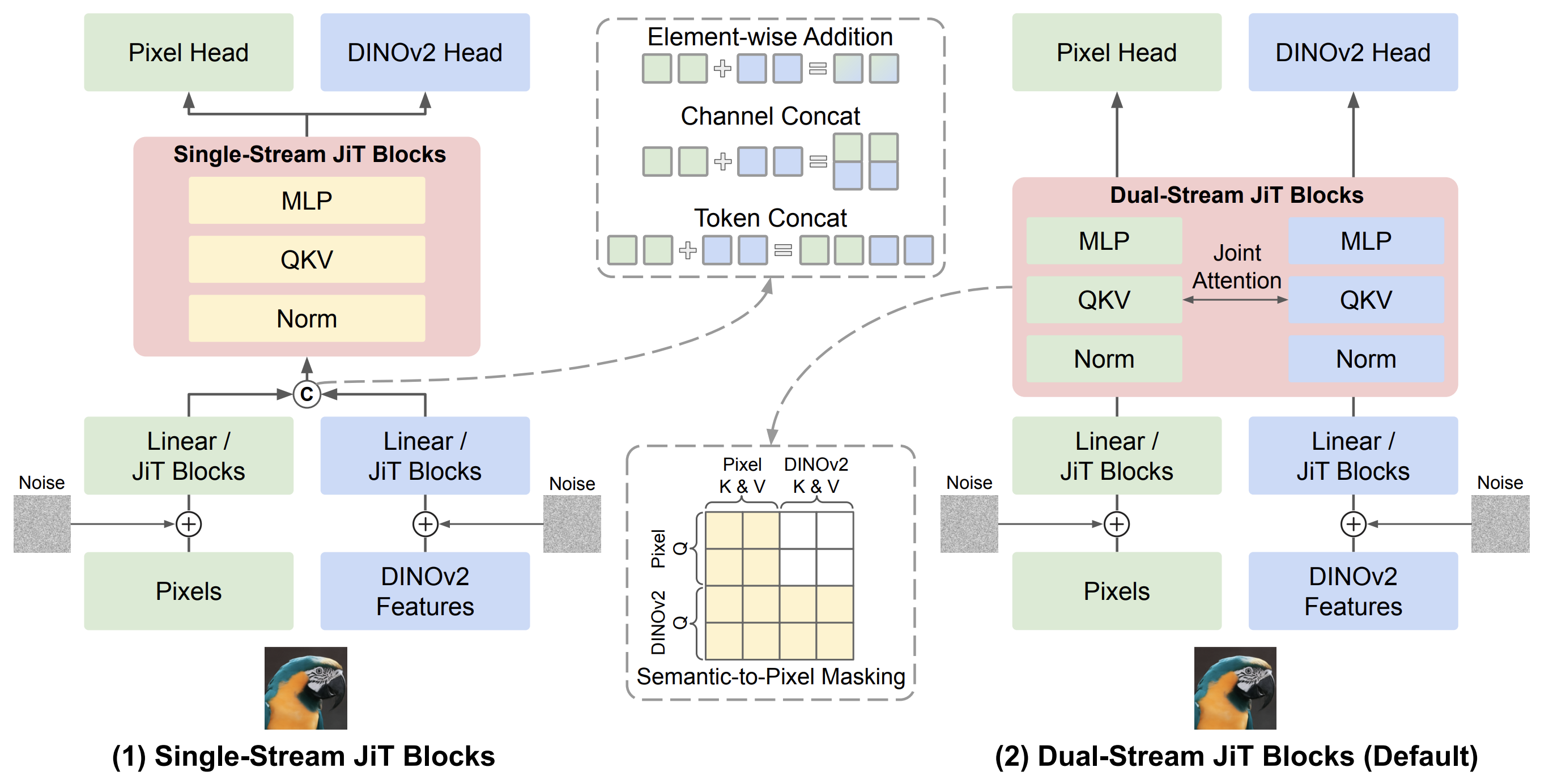
Exploring MLLM-Diffusion Information Transfer with MetaCanvas
Han Lin, Xichen Pan, Ziqi Huang, Ji Hou, Jialiang Wang, Weifeng Chen, Zecheng He, Felix Juefei-Xu, Junzhe Sun, Zhipeng Fan, Ali Thabet, Mohit Bansal, Chu Wang
arXiv Preprint, 2025
Paper | Project Page
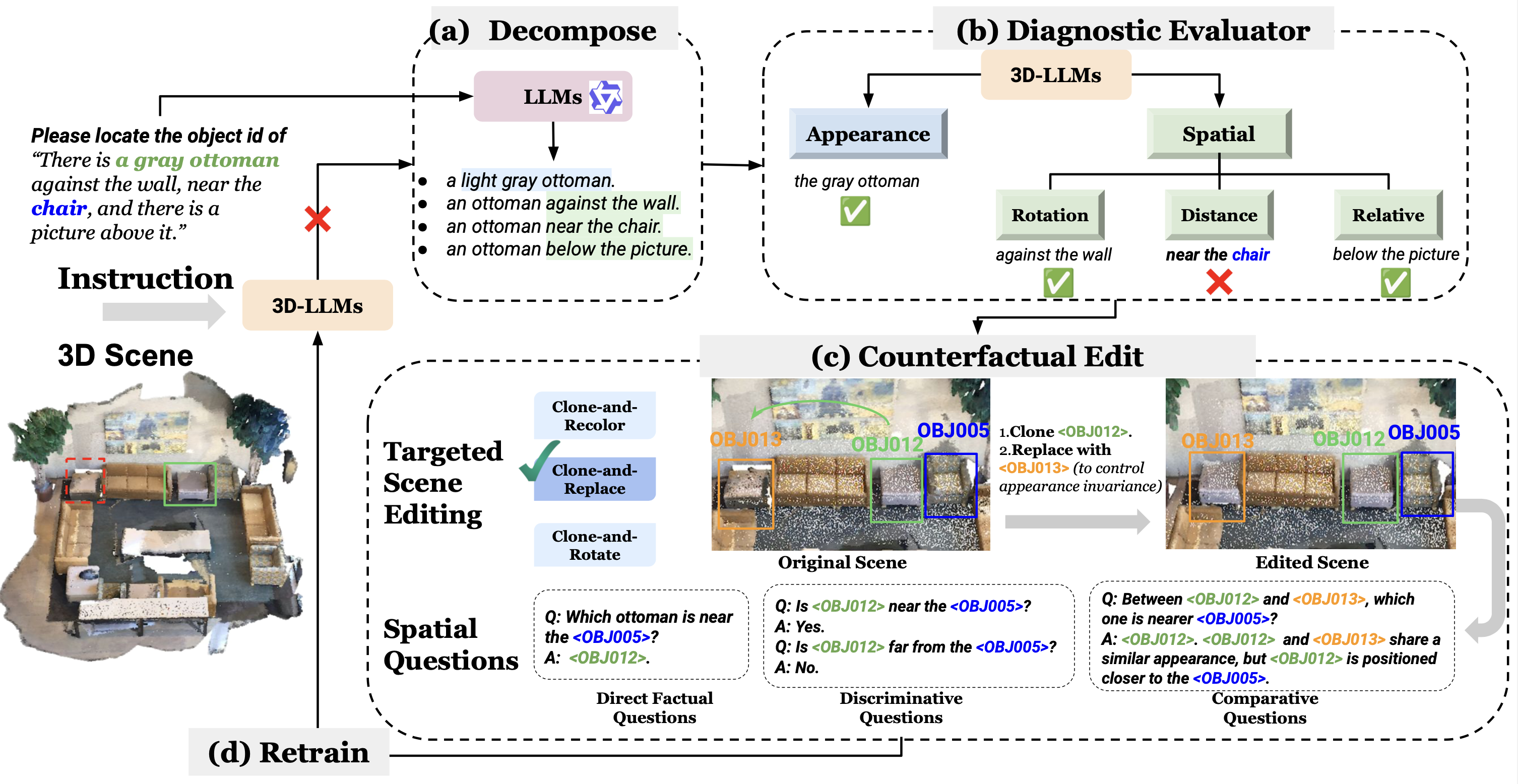
Planning with Sketch-Guided Verification for Physics-Aware Video Generation
Yidong Huang, Zun Wang, Han Lin, Dong-Ki Kim, Shayegan Omidshafiei, Jaehong Yoon, Yue Zhang, Mohit Bansal
arXiv Preprint, 2025
Paper | Project Page | Code
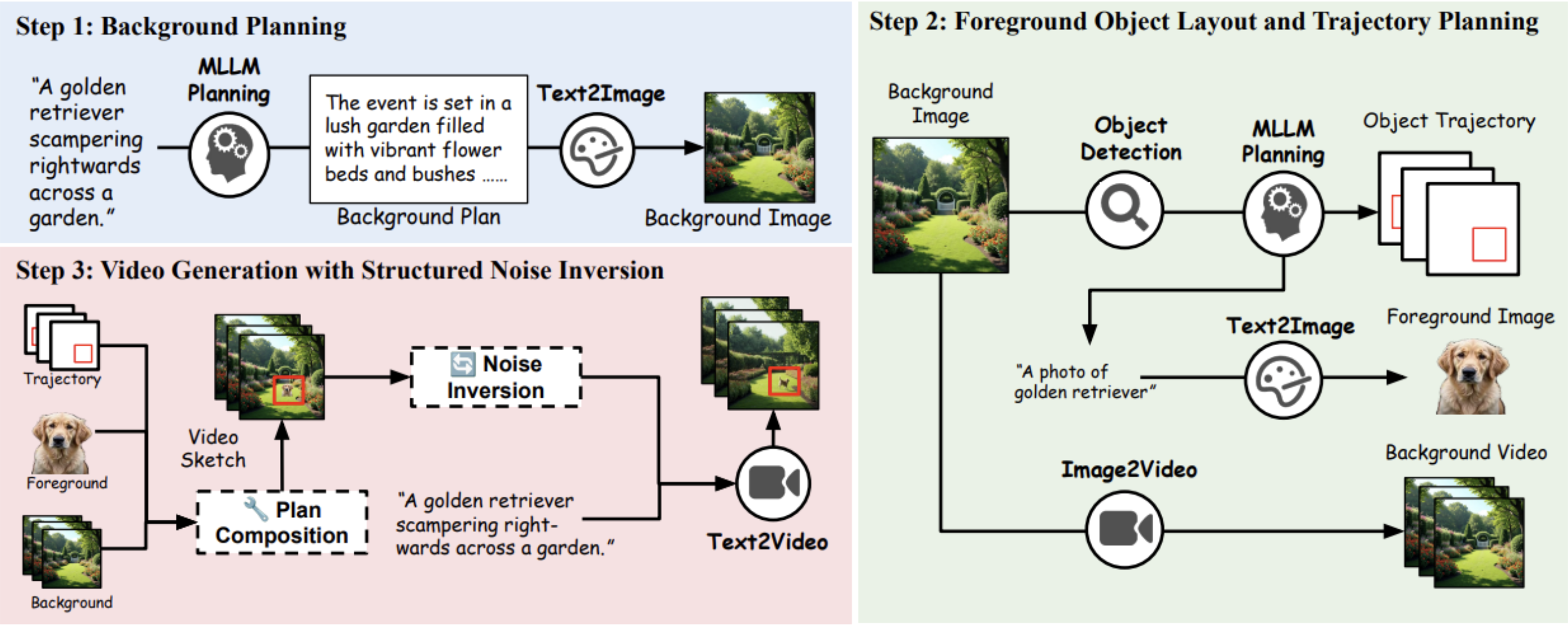
Training-Free Guidance in Text-to-Video Generation via Multimodal Planning and Structured Noise Initialization
Jialu Li*, Shoubin Yu*, Han Lin*, Jaemin Cho, Jaehong Yoon, Mohit Bansal
arXiv Preprint, 2025
Paper | Project Page | Code
Publications
AnchorWeave: World-Consistent Video Generation with Retrieved Local Spatial Memories
Zun Wang, Han Lin, Jaehong Yoon, Jaemin Cho, Yue Zhang, Mohit Bansal
ECCV 2026
Paper | Project Page | Code
EPiC: Efficient Video Camera Control Learning with Precise Anchor-Video Guidance
Zun Wang, Jaemin Cho, Jialu Li, Han Lin, Jaehong Yoon, Yue Zhang, Mohit Bansal
ICML 2026
Paper | Project Page | Code

A Benchmark of Expert-Level Academic Questions to Assess AI Capabilities
Center for AI Safety, Scale AI \& HLE Contributors Consortium
Nature 2026
Paper | Project Page

Bifrost-1: Bridging Multimodal LLMs and Diffusion Models with Patch-level CLIP Latents
Han Lin, Jaemin Cho, Amir Zadeh, Chuan Li, Mohit Bansal
NeurIPS 2025
Paper | Project Page | Code
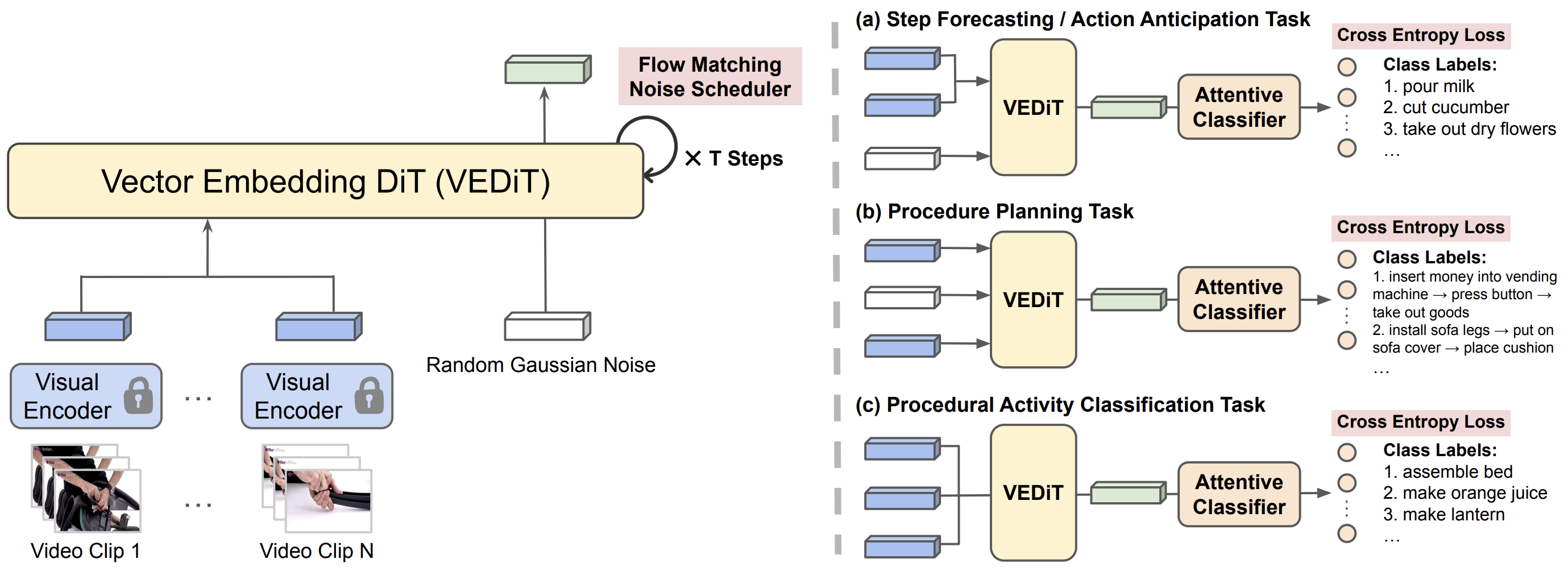
CTRL-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model
Han Lin*, Jaemin Cho*, Abhay Zala, Mohit Bansal
ICLR 2025, (Oral, Top 1.8%)
Paper | Project Page | Code | Video | Oral Talk
DreamRunner: Fine-Grained Storytelling Video Generation with Retrieval-Augmented Motion Adaptation
Zun Wang, Jialu Li, Han Lin, Jaehong Yoon, Mohit Bansal
AAAI 2025
Paper | Project Page | Code
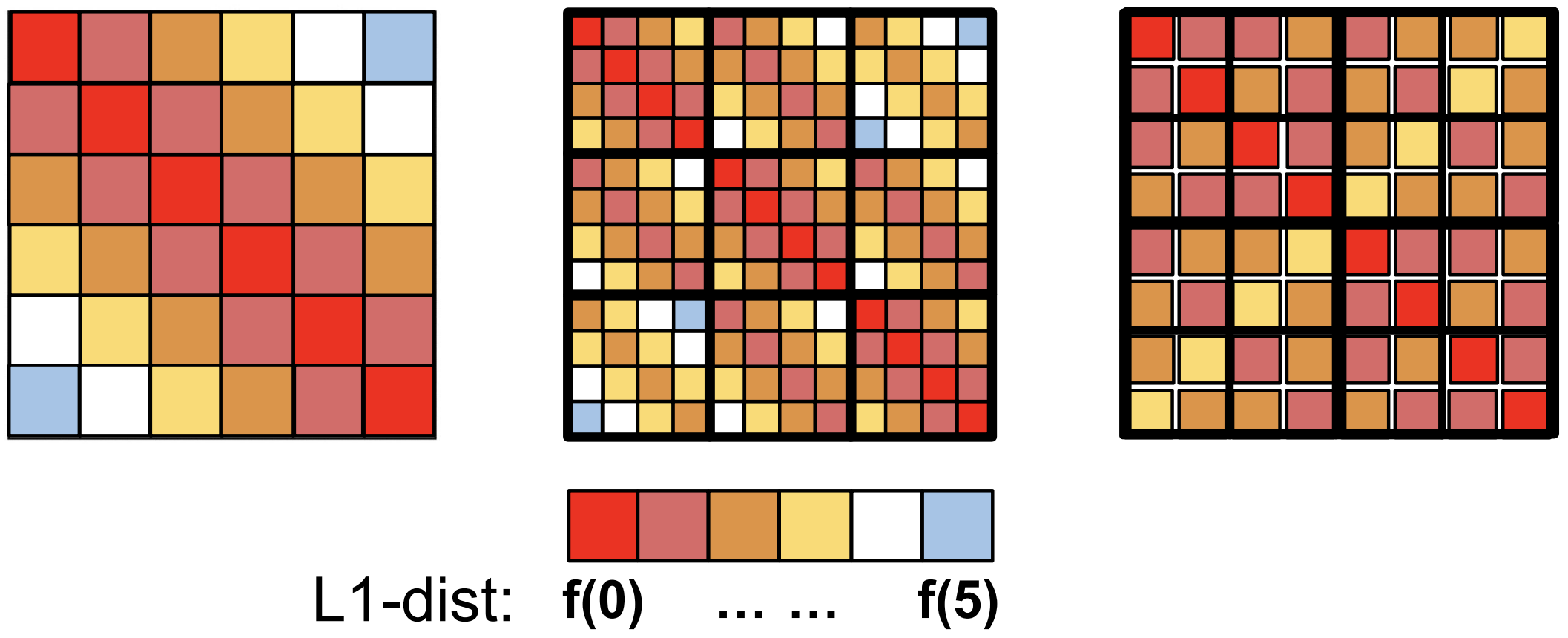
VideoDirectorGPT: Consistent Multi-Scene Video Generation via LLM-Guided Planning
Han Lin, Abhay Zala, Jaemin Cho, Mohit Bansal
COLM 2024
Paper | Project Page | Code
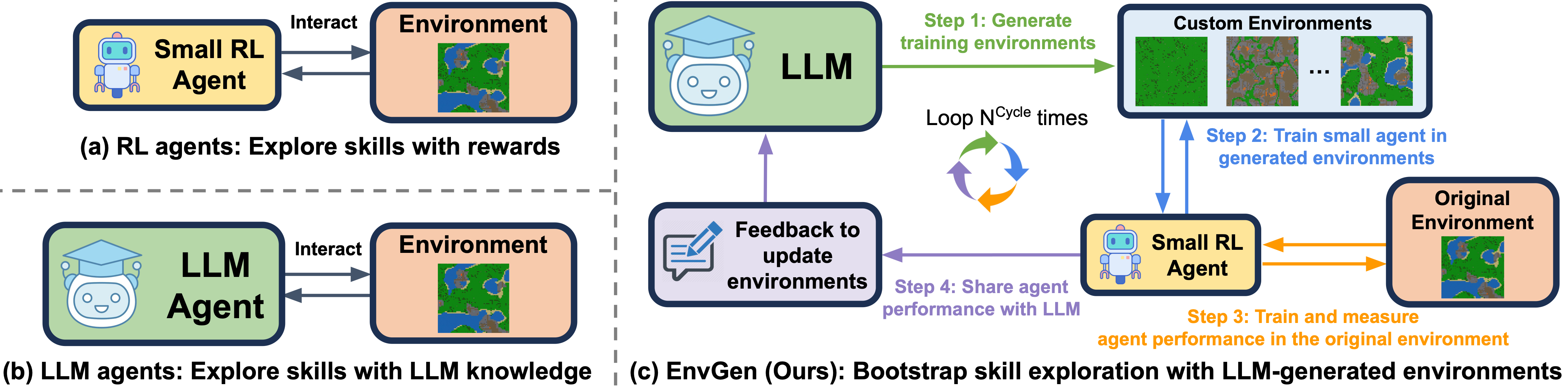
EnvGen: Generating and Adapting Environments via LLMs for Training Embodied Agents
Abhay Zala*, Jaemin Cho*, Han Lin, Jaehong Yoon, Mohit Bansal
COLM 2024
Paper | Project Page | Code
DiagrammerGPT: Generating Open-Domain, Open-Platform Diagrams via LLM Planning
Abhay Zala, Han Lin, Jaemin Cho, Mohit Bansal
COLM 2024
Paper | Project Page | Code

Efficient Graph Field Integrators Meet Point Clouds
Krzysztof Choromanski*, Arijit Sehanobish*, Han Lin*, Yunfan Zhao*, Eli Berger, Alvin Pan, Tetiana Parshakova, Tianyi Zhang, David Watkins, Valerii Likhosherstov, Somnath Basu Roy Chowdhury, Avinava Dubey, Deepali Jain, Tamas Sarlos, Snigdha Chaturvedi, Adrian Weller
ICML 2023
Paper | Code | Video

Active Tactile Exploration for 3D Object Recognition
Jingxi Xu*, Han Lin*, Shuran Song, Matei Ciocarlie
ICRA 2023
Paper | Project Page | Video
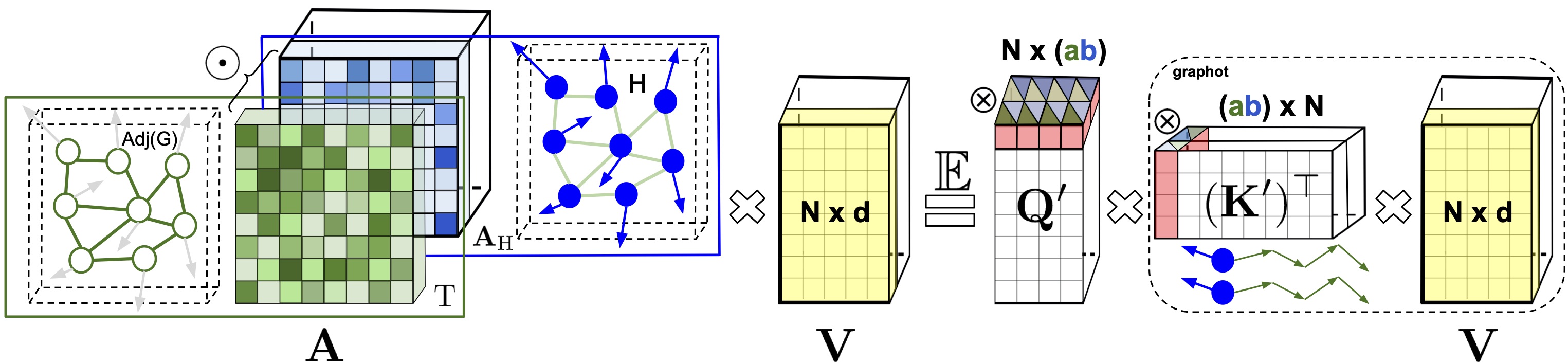
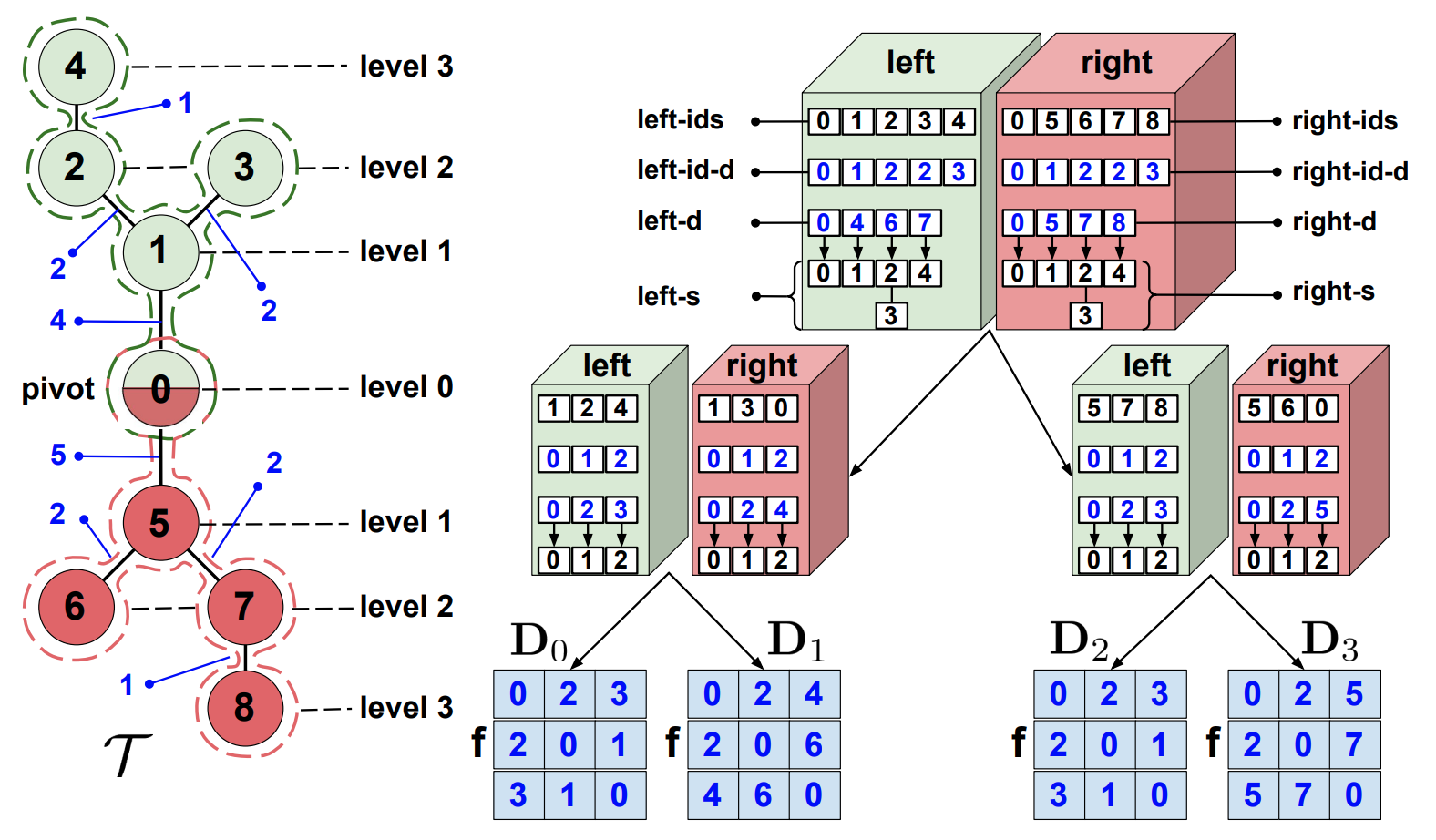
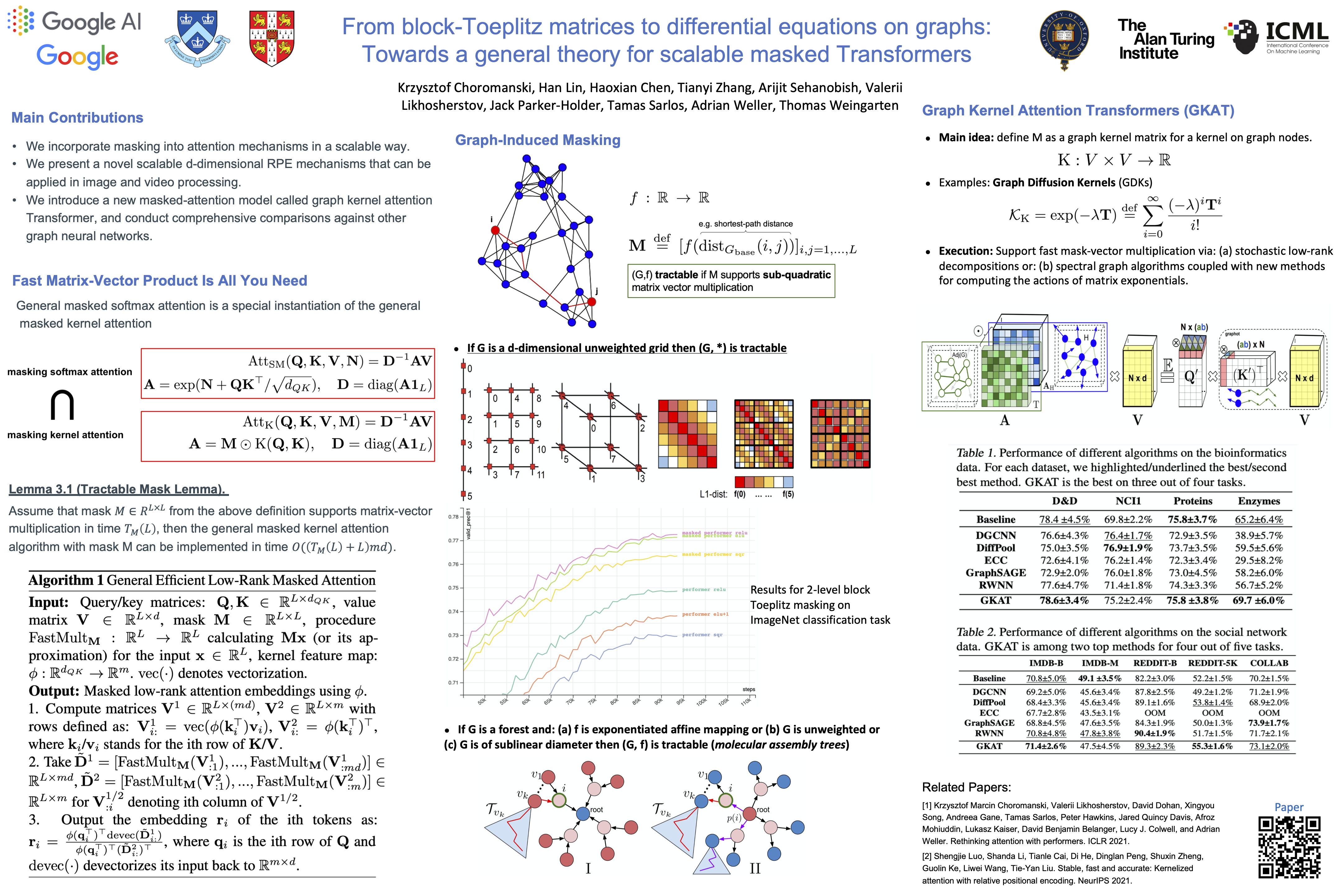
From Block-Toeplitz Matrices to Differential Equations on Graphs: Towards a General Theory for Scalable Masked Transformers
Krzysztof Choromanski*, Han Lin*, Haoxian Chen*, Tianyi Zhang, Arijit Sehanobish, Valerii Likhosherstov, Jack Parker-Holder, Tamas Sarlos, Adrian Weller, Thomas Weingarten
ICML 2022
Paper | Code | Poster | Video
{kind=link}
* Equal contribution.
Education
![]()
University of North Carolina at Chapel Hill
Aug 2023 - Exp. May 2028
Ph.D. in Computer Science
MURGe-Lab, advised by Prof. Mohit Bansal
![]()
Columbia University
2021 - 2023
M.S. in Computer Science (Machine Learning Track)
DVMM Lab, advised by Prof. Shih-Fu Chang
Supervised Masked Knowledge Distillation for Few-Shot Transformers, CVPR 2023
ROAM Lab, advised by Prof. Matei Ciocarlie and Prof. Shuran Song
Active Tactile Exploration for 3D Object Recognition, ICRA 2023
![]()
Columbia University
2018 - 2020
M.S. in Financial Engineering
![]()
Central University of Finance and Economics
2014 - 2018
B.S. in Financial Engineering
Experience
![]()
Meta
May 2025 - Dec 2025, Research Scientist Intern, Movie Gen Team, MSL
Exploring MLLM-Diffusion Information Transfer with MetaCanvas, under review
May 2024 - Dec 2024, Research Scientist Intern, JEPA Team, FAIR Lab
Latent Prediction Architecture For Procedural Video Representation Learning, ICLR 2025
![]()
Google DeepMind
2019 - 2024, Research Collaboration with Prof. Krzysztof Choromanski
Fast Tree-Field Integrators, NeurIPS 2024
Efficient Graph Field Integrators Meet Point Clouds, ICML 2023
From Block-Toeplitz Matrices to Differential Equations on Graphs, ICML 2022
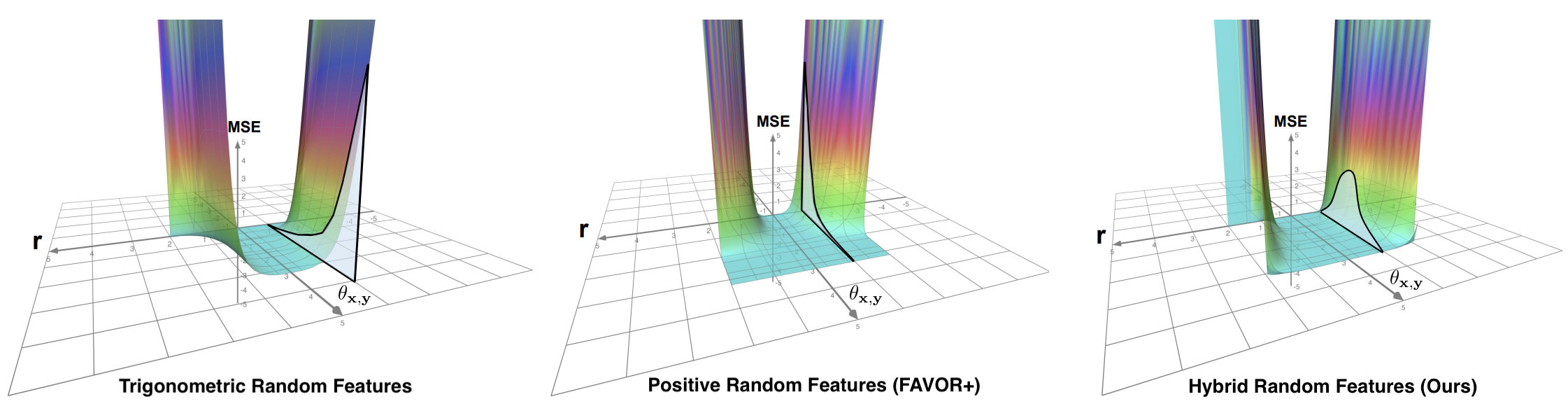
Hybrid Random Features, ICLR 2022
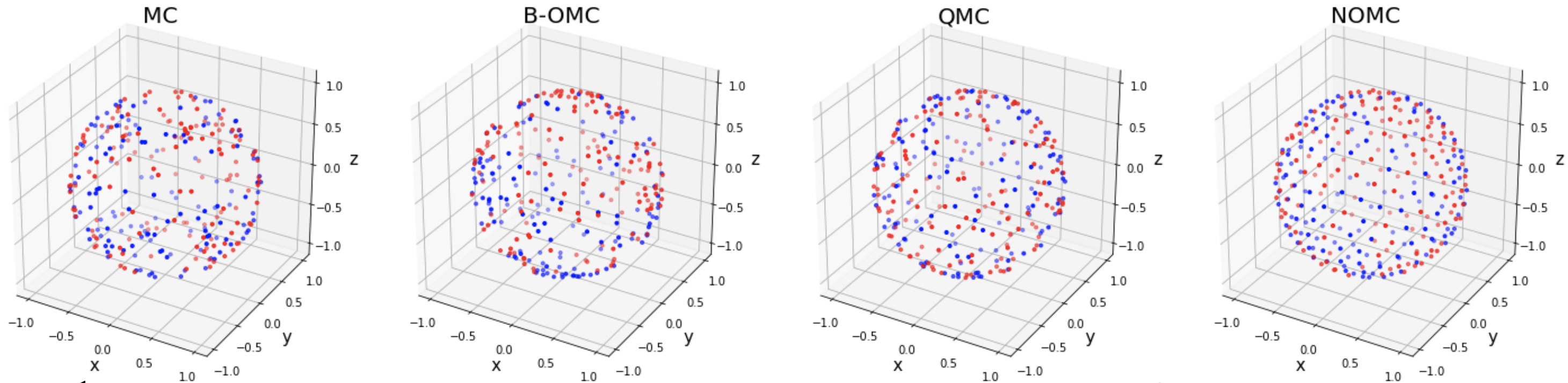
Demystifying Orthogonal Monte Carlo and Beyond, NeurIPS 2020
Professional Service
Reviewer:
NeurIPS 2022-2026, ICML 2022-2026, ICLR 2024-2025, CVPR 2025-2026, ICCV 2025, ECCV 2026
Workshop Organizer:
CVPR Workshop On Any-to-Any Multimodal Learning, 2026
Conference Volunteer:
Robotics: Science and Systems (RSS), 2022
Teaching Assistant
COMS 4231 Analysis of Algorithms, Columbia University, 2022 Fall
COMS 4732 Computer Vision 2: Learning, Columbia University, 2022 Spring
COMS 4721 Machine Learning for Data Science, Columbia University, 2022 Spring
QMSS 5073 Machine Learning for Social Science, Columbia University, 2021 Fall
IEOR 4007 Optimization Models & Methods for FE, Columbia University, 2019 Fall
IEOR 4418 Transportation Analytics & Logistics, Columbia University, 2019 Spring